SISTEM PENCARIAN BUKU BERDASARKAN MAKNA ISI BUKU
Masalah
Dalam memperoleh pengetahuan tidak lepas dari membaca, dan terkadang sangat sulit untuk mencari buku yang sesuai. Ketika kita sudah mendapatkan 1 buku yang sesuai, kita sering kesulitan dalam mencari buku yang pembahasannya sama. Ada yang judulnya hampir sama, akan tetapi untuk isinya berbeda dan tidak sesuai keinginan. Oleh karena itu, saya berpikir bagaimana kalau membuat sistem pencarian buku berdasarkan isi makna dari buku tersebut. Jadi nanti dalam sistem ini user akan mengupload ebook yang mereka punya, kemudian nanti akan muncul rekomendasi buku yang isi atau pembahasannya sama.
Literature Review
Berdasarkan masalah yang sudah dijelaskan diatas, diperlukan metode atau algoritma yang harus digunakan agar masalah tersebut terselaikan. Maka saya mengambil beberapa jurnal yang membahas tentang detection plagiarisme dan text mining, karena dalam sistem ini menggunakan pembacaan teks buku. Berikut jurnal-jurnal yang di review:
Deteksi Plagiarisme Dokumen Teks Menggunakan Algoritma SCAM
Algoritma SCAM memecah sebuah dokumen menjadi potongan kata, kemudian ditambahkan ke dalam urutan indeks dan digunakan untuk perbandingan dengan masukan dokumen baru. Dalam jurnal ini dokumen yang digunakan berformat *.txt, *.doc, *.docx, *.rtf. SCAM adalah singkatan dari Stanford Copy Analysis Mechanism.
Deteksi Plagiat Dokumen Menggunakan Algoritma Rabin-Karp
Algoritma Rabin-Karp adalah suatu algoritma pencarian string yang ditemukan oleh Michael Rabin dan Richard Karp. Algoritma ini menggunakan hashing untuk menemukan sebuah substring dalam sebuah teks. Hashing adalah metode yang menggunakan fungsi hash untuk mengubah suatu jenis data menjadi beberapa bilangan bulat sederhana. Jadi cara kerja dari algoritma hashing ini adalah mengubah string menjadi angka-angka. Contohnya adalah Firdaus, Hari bernilai 7864 dan Munir, Rinaldi bernilai 9802. Algoritma ini membandingkan nilai hash dari string masukan dan substring teks. Apabila sama, maka akan dilakukan perbandingan sekali lagi terhadap karakter-karakternya. Apabila tidak sama, maka substring akan bergeser ke kanan. Contohnya ada 2 buah kata yaitu “def” dan “eedefed”. Untuk karakter a=0, b=1, c=2, d=3, e=4, f=5, dst. Kemudian hasilnya di modulo dengan 3.
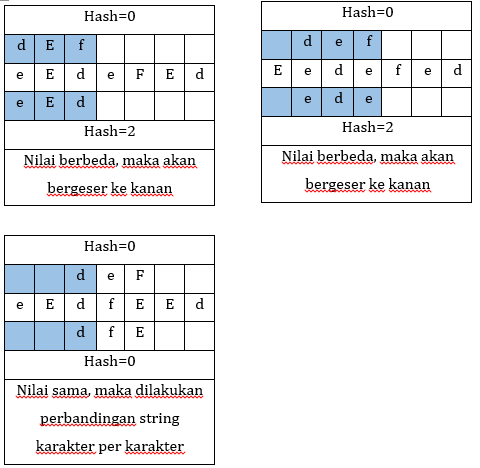
Dari perbandingan tersebut, ternyata karakter berbeda. Maka akan dilanjutkan bergeser ke kanan. Karena setelah kita mengetahui isi dari buku, maka dalam pencarian buku berdasarkan makna isi buku kita tinggal melakukan perbandingan berdasarkan kata yang sudah terbaca.
Pemanfaatan Teknik Supervised untuk Klasifikasi Teks Bahasa Indonesia
Dalam makalah ini mengggunakan dua metode yaitu: Naive Bayes dan k-Nearest Neighbor. Metode Naïve Bayes dikenal dengan algoritma klasifikasi simple Bayesian. Algoritma ini banyak digunakan karena terbukti efektif untuk kategorisasi teks, sederhana, cepat dan akurasi tinggi. Klasifikasi atau kategorisasi teks merupakan suatu proses penempatan suatu dokumen ke suatu kategori atau kelas sesuai dengan karakteristik dari dokumen tersebut. Dalam text mining, klasifikasi mengacu kepada aktifitas menganalisis atau mempelajari himpunan dokumen teks pre-classified untuk memperoleh suatu model atau fungsi yang dapat digunakan untuk mengelompokkan dokumen teks lain yang belum diketahui kelasnya ke dalam satu atau lebih kelas kelas pre-defined tersebut.
Penerapan Algoritma Jaro-Winkler Distance untuk Sistem Pendeteksi Plagiarisme pada Dokumen Teks Bahasa Indonesia
Pada jurnal ini membahas tentang algoritma Jaro-Winkler distance yang bertujuan untuk membandingkan kesamaan antar dokumen teks berbahasa Indonesia, sehingga dapat ditentukan sebuah dokumen tersebut plagiat atau tidak. Algoritma Jaro-Winkler distance merupakan varian dari Jaro distance metric yaitu sebuah algoritma untuk mengukur kesamaan antara dua string, biasanya algoritma ini digunakan di dalam pendeteksian duplikat. Semakin tinggi JaroWinkler distance untuk dua string maka semakin mirip dengan string tersebut. Nilai normalnya ialah 0 menandakan tidak ada kesamaan dan 1 yang menandakan adanya kesamaan. Jaro-Winkler distance menggunakan prefix scale (p) yang memberikan tingkat penilaian yang lebih dan prefix length (l) yang menyatakan panjang awalan yaitu panjang karakter yang sama dengan string yang dibandingkan sampai ditemukannya ketidaksamaan.
Pendeteksian Kesamaan pada Dokumen Teks Menggunakan Kombinasi Algoritma Enhanced Confix Stripping dan Algoritma Winnowing
Pada jurnal ini, algortima ECS digunakan untuk proses stemming teks yang dimasukkan dan algoritma Winnowing untuk menghitung tingkat kesamaannya (similarity) dengan dokumen dari database. Kerja dari algoritma ini adalah setiap kata yang terkandung dalam file teks diubah terlebih dahulu menjadi sebuah kumpulan nilai hash dengan teknik rolling hash. Nilai hash merupakan nilai numerik dari perhitungan ASCII untuk setiap karakter. Lalu kumpulan nilai hash yang disebut fingerprint tersebut digunakan untuk mendeteksi kemiripan antardokumen.
Daftar Pustaka:
Asmaraloka, T. J. (2014). Deteksi plagiarisme
Dokumen Teks Menggunakan Algoritma SCAM. Semarang.
Darujati, C., & Gumelar, B. A. (2012). Pemanfaatan
Teknik Supervised untuk Klasifikasi Teks Bahasa Indonesia. Surabaya.
Firdaus, B. H. (2008). Deteksi Plagiat Dokumen
Menggunakan Algoritma Rabin-Karp. Bandung.
Kornain, A., Yansen, F., & Tinaliah. (n.d.). Penerapan
Algoritma Jaro-Winkler Distance untuk Sistem Pendeteksi Plagiarisme pada
Dokumen Teks Berbahasa Indonesia.
Sion Sagala, A. C., Lydia, M. S., & Rahmat, R. F.
(n.d.). Pendeteksian Kesamaan pada Dokumen Teks Menggunakan Kombinasi
Algoritma Enhanced Confix Stripping dan Algoritma Winnowing.